Introduction
This technical document explores the intricate journey behind processing a search query on Google. It delves into the technical details involved in each stage, from the initial user input to the presentation of search results.
The target audience is IT working professionals and students seeking a foundational understanding of Google's search processes. Key areas covered include URL parsing, DNS resolution, secure communication protocols, and load balancing algorithms.
Initial Typing
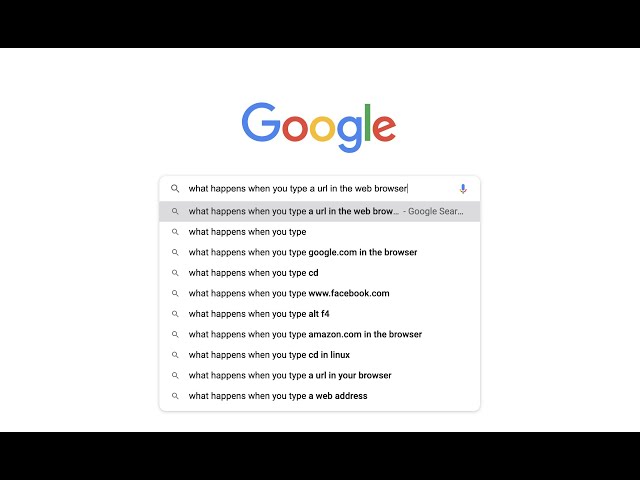
An address bar search starts with an initial typing phase. Typing, for instance, "G" prompts the browser to do one of the following:
- The browser starts looking into your history for words that start with the letter "G" and presents an auto-completed list.
- The browser does a search to the default search engine embedded into the browser itself.
URL Parsing
The browser then proceeds to parse the URL typed in the address bar. The browser asks two questions that aid in the parsing process:
- Is the input a URL?
- Is the input a search term?
If the input is a search term, Google does a simple search. The interest of this blog is a URL www.google.com. If the input is a URL, Google proceeds to visit the page.
Protocol
The browser then proceeds to examine the Hyper Text Transfer Protocol (HTTP) used. The two HTTP protocols supported are HTTP on port 80 and HTTPS on port 443. HTTPS (Secure) is a secure version of HTTP, therefore it is the recommended protocol.
The browser then proceeds to its HTTP Strict-Transport-Security (HSTS). The HSTS is a list that the browser caches on its local database. This list contains the famous web pages that force clients to communicate only via HTTPS. If Google is found in the list, HTTPS on port 443 is utilized. If not found, HTTP on port 80 is utilized.
TLS/SSL
HTTPS uses symmetric keys for encryption over the internet. Symmetric encryption uses a Public Key Infrastructure (PKI) to make assets secure. Below is the encryption process:
- The browser creates a session key, encrypts it with the server's public key, and sends the encrypted key to the server.
- The server uses its private key to decrypt the session key.
- The client and server use the session key to encrypt all further communications.
There is a risk that a malicious actor intercepts the connection and sends their own key. How does the client tell if the key is truly from Google's server?
A validation is needed to ascertain that this is Google's server key. A certificate authority (CA) is responsible for the signing of the server's public key. The CA generates a digital Secure Socket Layer (SSL) certificate that authenticates the website's identity.
DNS Lookup
A Domain Name System (DNS) turns domain names into IP addresses, which allow browsers to get to websites and other internet resources.
The domain name, protocol, and port are now established but something essential is missing. The browser needs the Internet Protocol (IP) address in order to make the connection.
We are assuming that this is the first time connecting to Google. Below are the steps taken to resolve a domain name to its IP address:
- The browser looks into its own cache in an attempt to find Google's IP address. This is a new connection so the IP does not exist in the cache.
- Google proceeds to look into the Operating System (OS) host file. The file resolves domain names into IP addresses.
- The client now attempts to find the IP from the gateway router. It sends IP packets to the router in an attempt to find Google's IP address.
Why the router? This is because routers support caching of website information based on available memory.
- The IP is not found therefore, the router has to send the IP packets over the internet. The Network Address Translation (NAT) translates the private IP address into a public IP address before sending the packets over the external network.
- The router adds a NAT entry so that it can remember the private IP address on response.
- The DNS server returns Google's IP address to the router once found. The router sends it to the client. Now the client has the IP address of Google!
TCP/IP
Before any data transmits, a Transmission Control Protocol (TCP) connection is established.
TCP/IP is a model that defines how devices should transmit data between them. The connection happens between the client and the server. The process is known as a TCP handshake. Below are the steps of the TCP handshake:
- The client contains a sequence number (SYN) that it sends to the server e.g. 400.
- A sequence number is a counter used to keep track of any bytes sent by a host.
- The server responds to the client with its own SYN/acknowledgement (ACK) e.g. 200/401.
- In turn, the client acknowledges the SYN/ACK sent by the server with an ACK response e.g. 201.
The client is now connected to the server ready to send and request data.
Firewalls
The client is trying to access Google's internal network by requesting pages from the server. Malicious actors also try to carry out cyber attacks on Google's infrastructure.
A firewall is therefore needed. A firewall is a system designed to prevent unauthorized access from a private network. The firewall creates a safety barrier between the private network and the public internet.
A firewall works by filtering incoming data. The firewall employs rules to determine if the data is allowed to enter a network. The rules are known as Access Control Lists (ACL).
The HTTPS port number is accepted by the ACL therefore the client is permitted into the internal network.
Load Balancer
Google as a search engine receives tonnes of requests every second. Suppose only a single server handles the incoming request, can it handle it all?
The answer is NO. A load balancer is needed to distribute incoming requests across multiple servers. The load balancer achieves this by use of various load balancing algorithms.
The client interacts with the IP address of the load balancer. The IP of the internal servers are unknown to the client.
Web Servers
The web server receives the HTTP GET request from the client through the load balancer. A web server is computer software and underlying hardware that accepts requests via HTTP or its secure version HTTPS.
The web server contains the Google web pages and all static files. The web server’s primary focus is to receive and respond to HTTP requests coming to the server. It parses HTML content, renders images, etc. The server relays any other processing power to an application server.
HTML Parsing
Now that the client has accessed the web server the HTML parsing begins. Parsing is the process of reading the HTML documents and extracting its structural components.
The client's request attempts to get the HTML page however Google is not only made up of HTML content.
The request discovers that there are other content such as Cascading Style Sheets (CSS) files, JavaScript (JS) files, and image content.
The TCP connected client sends another GET request for the additional files.
The server receives the requests and replies with the fully structured page.
Application Server
Google has complex business logic so it needs an application server. An application server acts as a container of the business logic. It facilitates access to and performance of the business application.
For instance, the client wants to see a particular dataset from google.com. The web server contains static pages with no logic so this request is passed onto the application server. The application server contains the necessary logic to arrive at that requested data.
Database
Depending on the business needs a database is always needed. A database is a collection of structured information or data stored in a computer system. Two types of databases exist namely:
- Structured Query Language (SQL) databases
- NoSQL databases
The database contains organized Google's platform user data and other data for running Google. Some of the data found in the database are:
- User profiles
- Search history
Conclusion
This document has focused on the initial stages of Google Search functionality, offering insights into the underlying technical processes. While this exploration provides a foundation for understanding, the vastness of web technology offers countless opportunities for further exploration. Readers are encouraged to leverage the information presented here as a springboard for deeper exploration into specific aspects of the internet's infrastructure.